Abstract
While large-scale robotic systems typically rely on textual instructions for tasks, this work explores a different approach: Can robots infer the task directly from observing humans? This shift necessitates the robot's ability to decode human intent and translate it into executable actions within its own physical constraints and environment.
We introduce Vid2Robot, a novel end-to-end video-based learning framework for robots. Given a video demonstration of a manipulation task and current visual observations, Vid2Robot directly produces robot actions. This is achieved through a unified representation model trained on a large dataset of human video and robot trajectory. The model leverages cross-attention mechanisms to fuse prompt video features to the robot's current state and generate appropriate actions that mimic the observed task. To further improve policy performance, we propose auxiliary contrastive losses that enhance the alignment between human and robot video representations.
We evaluate Vid2Robot on real-world robots, demonstrating a 23% improvement in performance compared to other video-conditioned policies when using human demonstration videos. Additionally, our model exhibits emergent capabilities, such as successfully transferring observed motions from one object to another, and long-horizon composition, thus showcasing its potential for real-world applications.
Cross Object Motion Transfer
Using Vid2Robot, you can enable verb transfer to other objects. Here are some examples of verbs like place upright, pick from drawer, place into the drawer and more.
Robot sees the Chips bag in its view, "picks it up and places it on the counter".
Robot sees the Green Can in its view and "knocks it over".
Robot sees the Banana in its view and "places it in the top drawer".
Robot sees the Top drawer open in its view and "closes the drawer".
Robot sees the Soft Pink Piggy Toy in the drawer open in its view and "picks and places it on the counter".
Robot sees the Banana in its view and attempts to "place it upright".
Long Horizon Task Composition
We can solve long horizon task compositions by combining prompt videos. Here we showcase long horizon task compositions on open, place and close drawers, move object close to another object sequentially, knocking and placing upright:
Robot sees the Coke Can, Chips bag and Rxbar in its view and first moves the Chips bag and then the Rxbar near the coke can.
Robot sees the Green Soda Can in its view and executes knocking it over and then placing it upright.
Robot sees the Green Soda Can in its view and executes placing it upright and then knocking it over.
Architecture
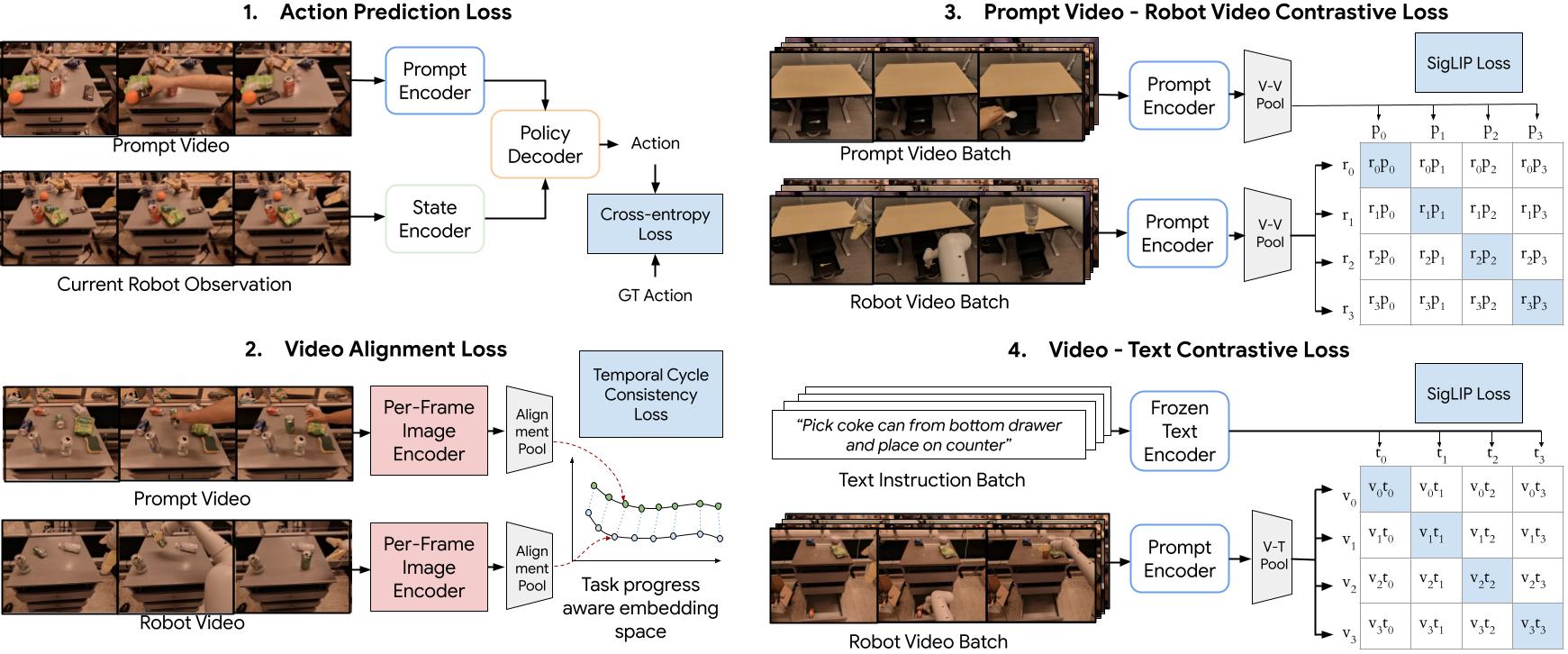
Our policy takes as input the prompt video and the current robot state and outputs robot actions. It consists of four modules: (1) prompt video encoder (2) robot state encoder, (3) state-prompt encoder, and (4) robot action decoder.
We show all the losses Vid2Robot is trained with and how each loss is connected to its different modules. Along with (1) the main action prediction loss, we apply three auxiliary losses: (2) temporal video alignment loss, (3) a contrastive loss between the prompt and robot video performing the same task, and (4) a contrastive loss between a prompt/robot video with the language embedding.
Dataset
To train a video-conditioned robot policy we need a datasetof pairs: prompt videos and robot trajectories
performing thesame task. In this work, we explore prompt videos where thetask is performed by both humans
and robots. To create thisdataset, we rely on three classes of data:
Robot-Robot: We pair existing robot-robot videos of the same task.
Hindsight Human-Robot: Here we use the task instruc-tions from the robot trajectories
dataset and ask one tofive human participants to perform the task and recorda demonstration video from the
robot’s perspective/view.
Co-located Human-Robot: In this case, a human and arobot perform the same task in the same
workspace. Weused this approach to collect human demonstrations androbot trajectories in diverse spaces such
as kitchens, livingrooms, and offices.
Failure Analysis
Vid2Robot is not perfect and has its limitations.
Here are some failure cases where Vid2Robot fails to perform the task as shown in the prompt video.
Some common failures cases are of self-occlusion, grasping errors, incorrect object identification, or
ambiguous task shown in the prompt video.
The prompt video is in blue frame and unsuccessful rollout is in red frame below.
BibTeX
@misc{jain2024vid2robot,
title={Vid2Robot: End-to-end Video-conditioned Policy Learning with Cross-Attention Transformers},
author={Vidhi Jain and Maria Attarian and Nikhil J Joshi and Ayzaan Wahid and Danny Driess and Quan Vuong and Pannag R Sanketi and Pierre Sermanet and Stefan Welker and Christine Chan and Igor Gilitschenski and Yonatan Bisk and Debidatta Dwibedi},
year={2024},
eprint={2403.12943},
archivePrefix={arXiv},
primaryClass={cs.RO}
}